I extended a research compiler framework for automatic differentiation (AD) to support distributed execution across multiple cores using OpenMP and MPI. The goal was to allow users to define any numerical function, regardless of input dimensionality, and automatically generate C code that computes derivatives in parallel.
Implementing Forward and Reverse Mode AD
I implemented both Forward Mode and Reverse Mode AD directly in the compiler. When a user-defined function is passed in, the compiler performs expression-level parsing to extract the computation graph and generates a differentiated version of the function using the chain rule.
- Forward Mode:
Each input variable is seeded with a derivative vector (tangent), and derivatives are propagated alongside primal values during a single forward pass. This mode is efficient when the number of inputs is small relative to outputs.
The compiler automatically generates a functiond_user_functhat computes both function outputs and directional derivatives. I parallelized this loop using OpenMP by assigning a chunk of directional derivative computations to each thread. - Reverse Mode:
Reverse mode records a “tape” of the computation during the forward pass. During the backward pass, gradients are accumulated in reverse order using adjoints. This mode is ideal when the number of outputs is small.
I implemented tape recording using a stack-based memory structure and inserted OpenMP directives to parallelize gradient accumulation where possible. Reverse mode requires more memory and careful synchronization, especially when scaling with MPI across multiple processes.
Scaling Experiments
To evaluate the performance of the generated code, I conducted both weak scaling and strong scaling experiments:
- Weak Scaling: Each core handles 1 million derivative calls independently.
- Strong Scaling: The total number of derivative calls is fixed at 1 million and distributed across more cores.
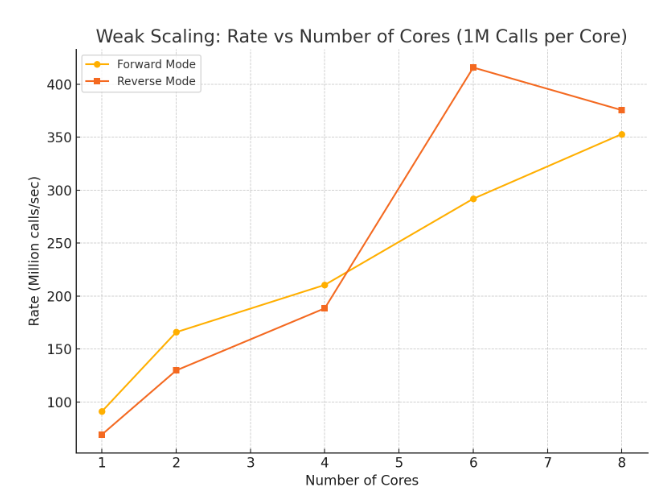 Weak scaling performance of forward and reverse mode differentiation with 1M calls per core.
Weak scaling performance of forward and reverse mode differentiation with 1M calls per core.
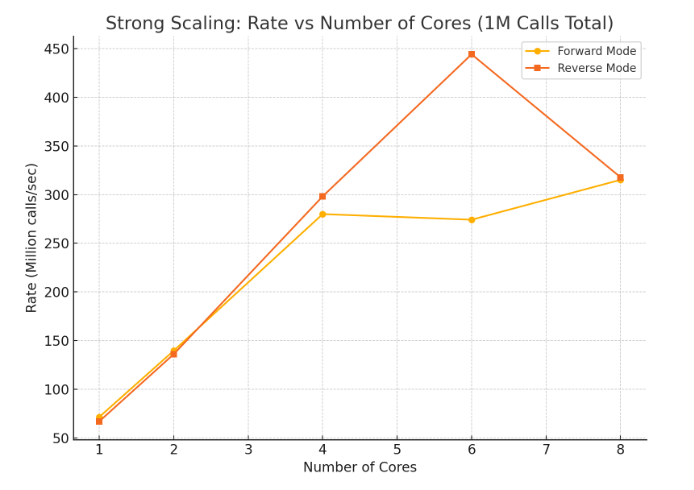 Strong scaling performance with 1M total calls across increasing cores. Reverse mode scales well but shows diminishing returns beyond 6 cores due to shared tape write contention.
Strong scaling performance with 1M total calls across increasing cores. Reverse mode scales well but shows diminishing returns beyond 6 cores due to shared tape write contention.
Learnings & Takeaways
This project taught me how compilers can be extended to automate parallelization and differentiation for numerical computing. I learned to:
- Work with compiler-generated IR and symbol tables.
- Translate mathematical computation graphs into parallel C code.
- Use OpenMP for shared-memory threading and MPI for distributed execution.
- Understand the trade-offs between forward and reverse mode AD in real-world workloads.
I found it especially rewarding to integrate systems-level parallelism with compiler-generated numerical routines. This project highlighted how AD, parallel computing, and code generation can come together to make large-scale gradient-based computation practical and scalable.